Pre-training vs Fine-Tuning vs In-Context Learning of Large
$ 19.00
4.7(552)In stock
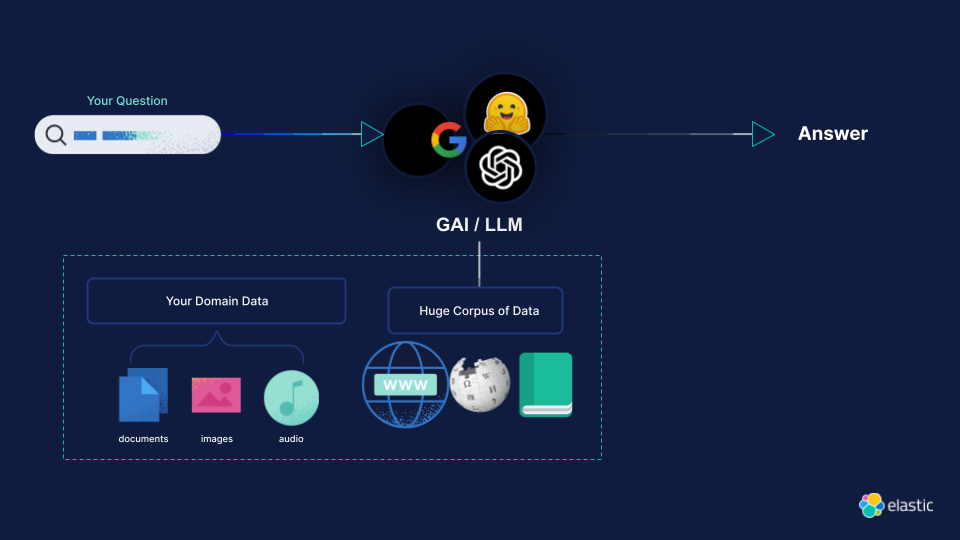
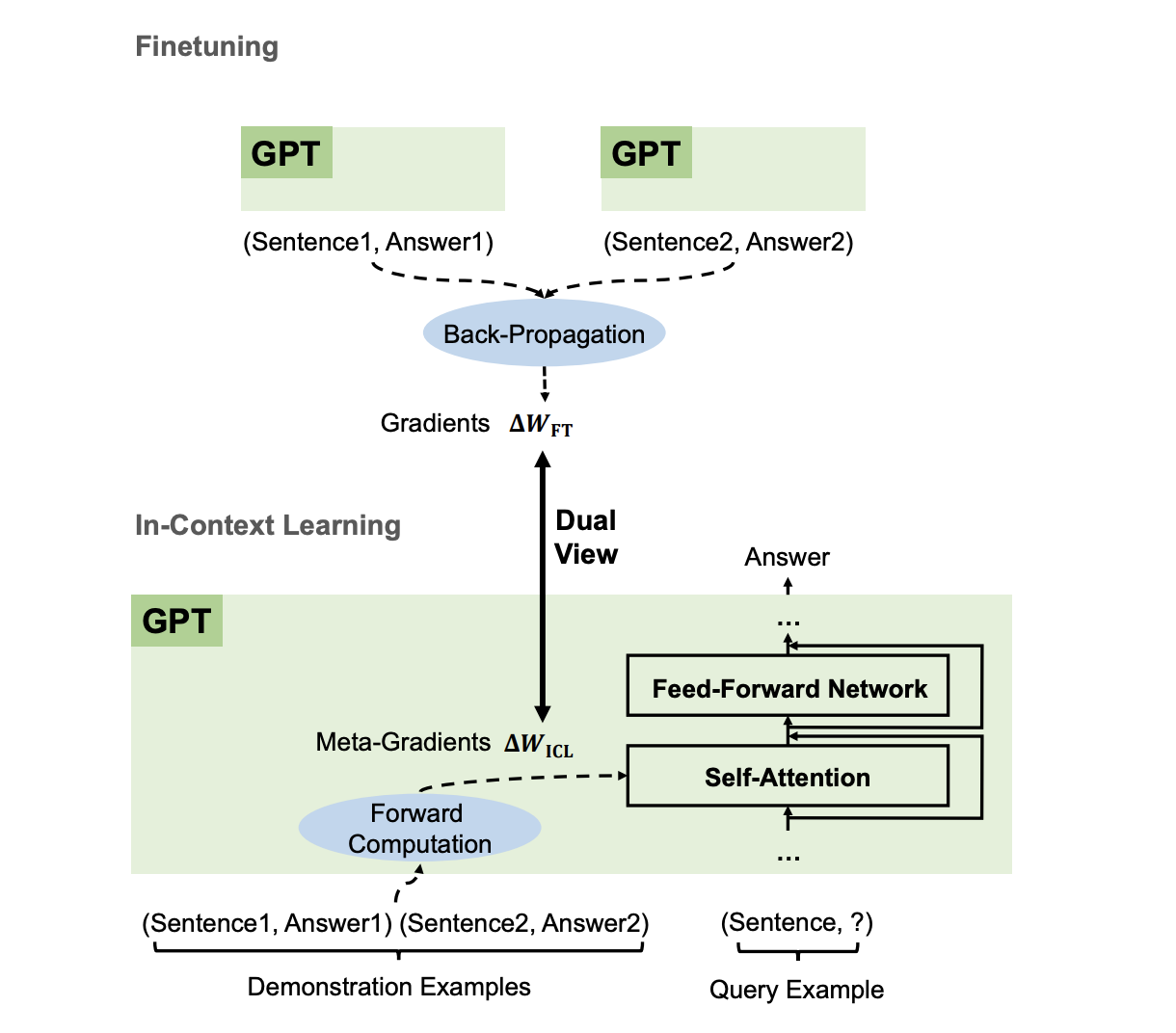
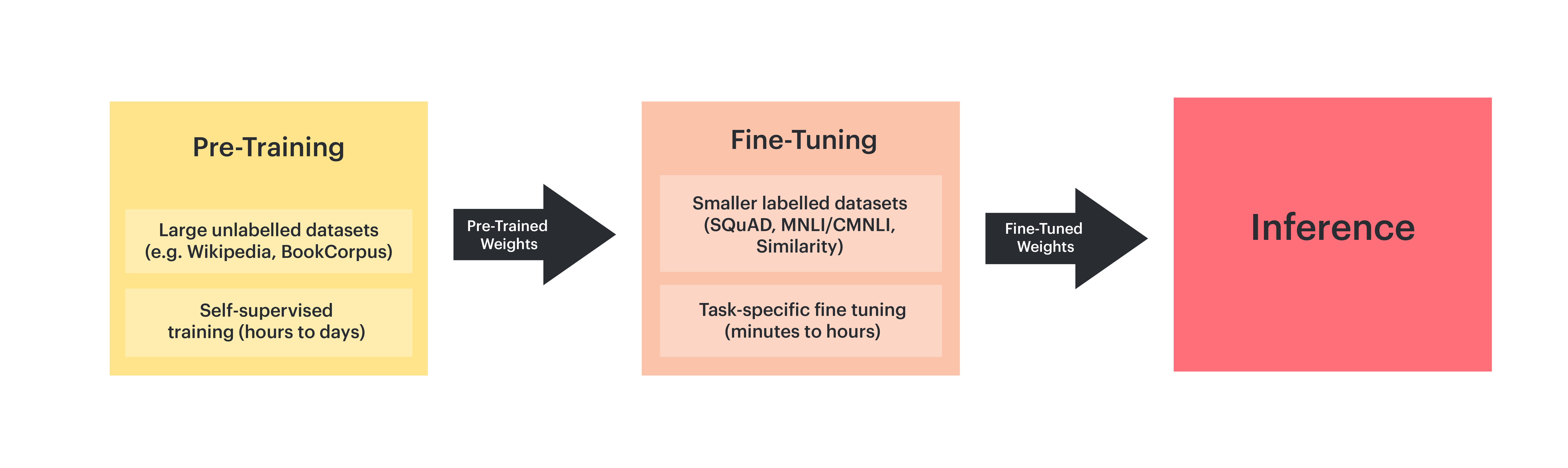
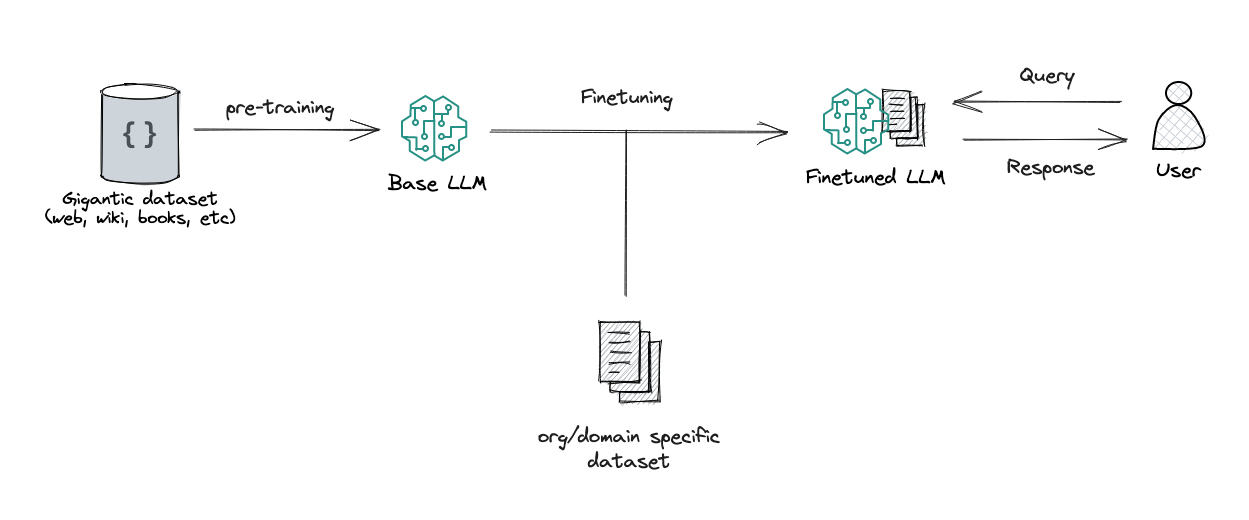
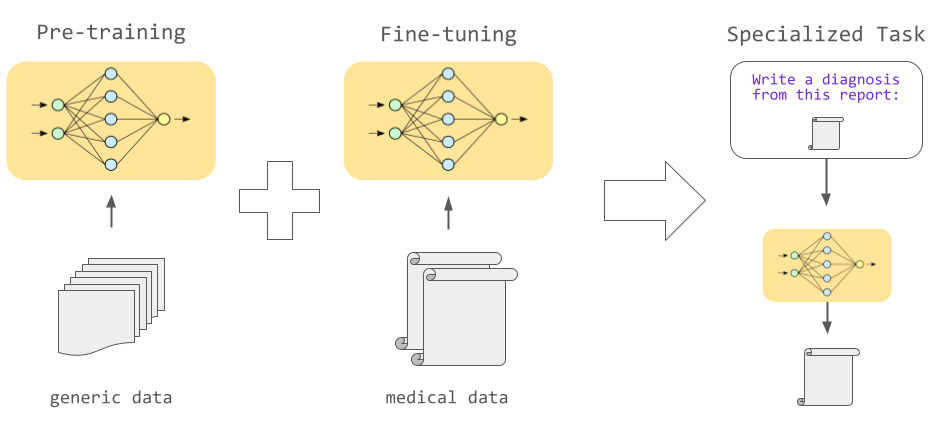
Large language models are first trained on massive text datasets in a process known as pre-training: gaining a solid grasp of grammar, facts, and reasoning. Next comes fine-tuning to specialize in particular tasks or domains. And let's not forget the one that makes prompt engineering possible: in-context learning, allowing models to adapt their responses on-the-fly based on the specific queries or prompts they are given.
Domain Specific Generative AI: Pre-Training, Fine-Tuning, and RAG — Elastic Search Labs
What is In-context Learning, and how does it work: The Beginner's Guide
Articles Entry Point AI
Parameter-efficient fine-tuning of large-scale pre-trained language models
1. Introduction — Pre-Training and Fine-Tuning BERT for the IPU
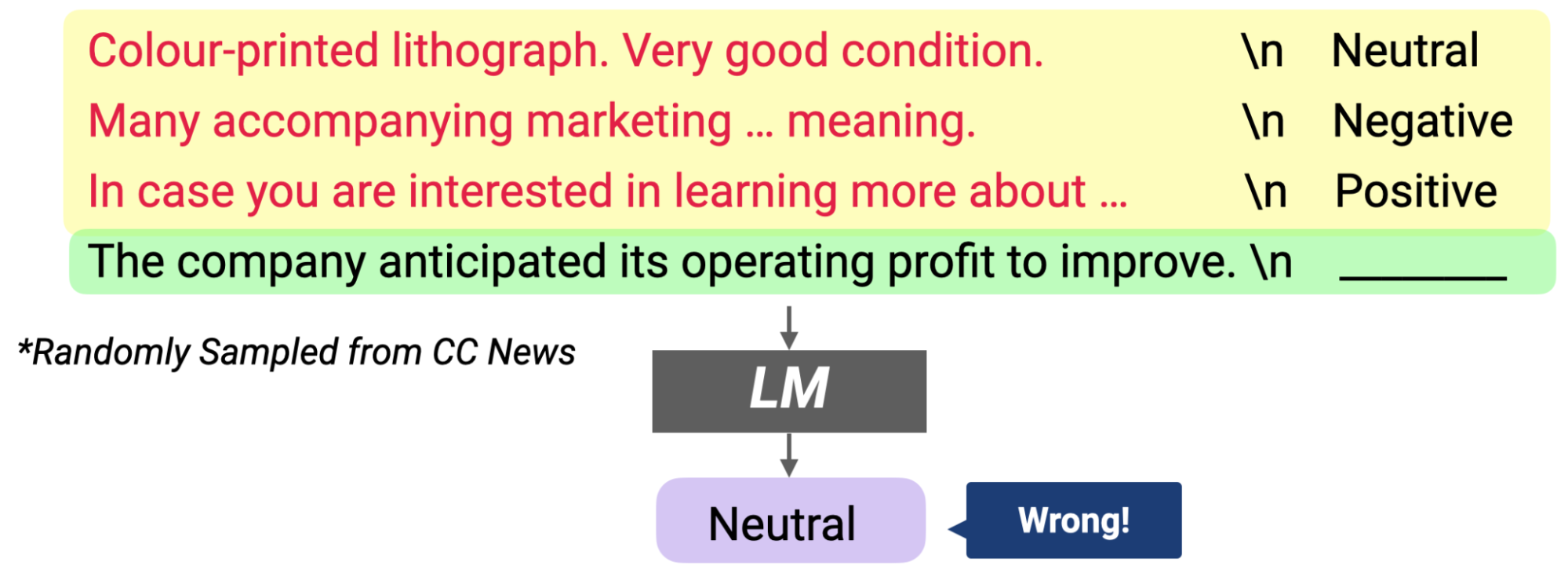
How does in-context learning work? A framework for understanding the differences from traditional supervised learning
RAG vs Finetuning — Which Is the Best Tool to Boost Your LLM Application?, by Heiko Hotz
Pretraining vs Fine-tuning vs In-context Learning of LLM (GPT-x
Training and fine-tuning large language models - Borealis AI